Light linear logics
Light linear logics are variants of linear logic characterizing complexity classes. They are designed by defining alternative exponential connectives, which induce a complexity bound on the cut-elimination procedure.
Light linear logics are one of the approaches used in implicit computational complexity, the area studying the computational complexity of programs without referring to external measuring conditions or particular machine models.
Contents |
Elementary linear logic
We present here the intuitionistic version of elementary linear logic, ELL. Moreover we restrict to the fragment without additive connectives.
The language of formulas is the same one as that of (multiplicative) ILL:
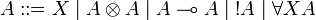
The sequent calculus rules are the same ones as for ILL, except for the rules
dealing with the exponential connectives:
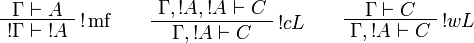
The depth of a derivation π is the maximum number of
 rules in a branch of π.
rules in a branch of π.
We consider the function K(.,.) defined by:
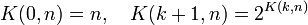 .
.
Theorem
If π is an ELL proof of depth d, and R is the corresponding ELL proof-net, then R can be reduced to its normal form by cut elimination in at most K(d + 1, | π | ) steps, where | π | is the size of π.
A function f on integers is elementary recursive if there exists an integer h and a Turing machine which computes f in time bounded by K(h,n), where n is the size of the input.
Theorem
The functions representable in ELL are exactly the elementary recursive
functions.
One also often considers the affine variant of ELL, called elementary affine logic EAL, which is defined by adding unrestricted weakening:
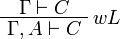
It enjoys the same properties as ELL.
Elementary linear logic was introduced together with light linear logic [1].
Light linear logic
We present the intuitionistic version of light linear logic LLL, without additive connectives. The language of formulas is:
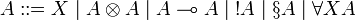
The sequent calculus rules are the same ones as for ILL, except for the rules
dealing with the exponential connectives:
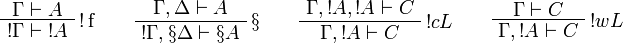
In the 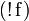 rule, Γ must contain at most one formula.
rule, Γ must contain at most one formula.
The depth of a derivation π is the maximum number of
and 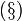 rules in a branch of π.
rules in a branch of π.
Theorem
If π is an LLL proof of depth d, and R is the corresponding LLL proof-net, then R can be reduced to its normal form by cut elimination in
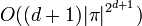 steps, where | π | is the size of π.
steps, where | π | is the size of π.
The class FP is the class of functions on binary lists which are computable in polynomial time on a Turing machine.
Theorem
The class of functions on binary lists representable in LLL is exactly FP.
In the literature one also often considers the affine variant of LLL, called light affine logic, LAL.
Soft linear logic
We consider the intuitionistic version of soft linear logic, SLL.
The language of formulas is the same one as that of ILL:
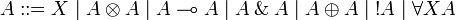
The sequent calculus rules are the same ones as for ILL, except for the rules
dealing with the exponential connectives:
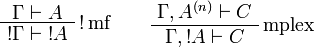
The rule mplex is the multiplexing rule. In its premise, A(n) stands for n occurrences of formula A. As particular instances of mplex for n = 0 and 1 respectively, we get weakening and dereliction:
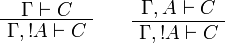
The depth of a derivation π is the maximum number of
rules in a branch of π.
Theorem
If π is an SLL proof of depth d, and R is the corresponding SLL proof-net, then R can be reduced to its normal form by cut elimination in
O( | π | d) steps, where | π | is the size of π.
Theorem
The class of functions on binary lists representable in SLL is exactly FP.
Soft linear logic was introduced in [2].